
Whereas DynamoDB is known for being advantageous for use cases where the scope and requirements are well defined in advance, it also offers the flexibility required to retrospectively adjust database querying capabilities without compromising on scalability and performance, should your business requirements change.
Nonetheless, a considered and methodical approach is always advised when approaching the creation of a single table design using Amazon DynamoDB. In this article, we detail our recommended approach to designing, modeling, and implementing a single table design that satisfies the needs of your organisation.
Querying DynamoDB efficiently using primary keys
Before designing the data model itself, it is important to understand how DynamoDB uses primary keys to uniquely identify entries in a table and execute queries efficiently.
A composite primary key typically consists of two attributes, a partition key and a sort key. The partition key value provided is used to determine within which partition the data is stored, with DynamoDB using an internal hash function to map the partition key value to a specific partition. Once the partition is defined, the sort key can be used to perform more complex operations when querying the database.
Whereas the partition key is quite rigid in that queries against this key only facilitate the ‘=’ operator, the sort key is more flexible as it is able to make use of multiple operators, including ‘BETWEEN’ and ‘BEGINS_WITH’.
Querying DynamoDB involves creating expressions to be evaluated against the database, most notably the key condition expression and the filter expression. The key condition expression prompts DynamoDB to leverage indexes to directly locate the items matching the condition provided, meaning it minimises the amount of data examined by scanning only the relevant portions of the table. However, notably, only fields that make up a primary key can be evaluated in a key condition expression.
Below is an example demonstrating some query parameters designed for a table named ‘Orders’. The key condition expression involves comparing against a ‘CustomerID’ field (the partition key) and an ‘OrderDate’ field (the sort key). The operand values are passed through to the key condition expression via the ‘ExpressionAttributeValues’ object. In the example below, the values themselves are hardcoded, though you would typically populate these with parameters passed through to the function invoking the query.
{
TableName: 'Orders',
KeyConditionExpression: 'CustomerID = :customerID AND OrderDate BETWEEN :startDate AND :endDate',
ExpressionAttributeValues: {
':customerID': {
S: '12345',
},
':startDate': {
S: '2023-01-01',
},
':endDate': {
S: '2023-12-31',
}
}
}
Filter expressions are optional expressions that can be applied to further refine the results. They can be used to evaluate against any field within a table, although this expression is only applied after the initial query operation has retrieved items based on the key condition expression.
This is an important consideration as queries that don’t effectively utilise key condition expressions and instead rely heavily on filter expressions to identify desired items are particularly inefficient as they involve evaluating unnecessarily large amounts of data.
Ultimately, with this in mind, the goal when defining a data model is to avoid using filter expressions where possible. This means ensuring that, when written to the database, the partition key and sort key of each item are constructed in such a way that enables you to access the items required purely by querying the primary key.
This article may be of interest to you: “Why choose Amazon DynamoDB? Exploring its benefits and potential trade-offs”
4 key steps for efficient single table design in DynamoDB
In this section, we will explore four fundamental steps to design a single table in DynamoDB that meets your organisation’s requirements and streamlines data access operations:
1. Define use case and data entities
The first step when designing a table is to thoroughly assess your use case, establish the individual data entities that are necessitated by your requirements, and identify the fields to be included within each entity.
In our simple example scenario, we intend to build a register for a trading platform which contains all user accounts and assets that exist within the platform. It must also maintain a record of each user’s ownership of individual assets via stock balance entries, in addition to building up a transaction history each time a trade is made via the creation of stock posting entries for involved parties.
After some consideration, we decide upon the following data entities, comprised of the specified fields:
- Account: AccountId, UserName
- Asset: AssetId, Name, Description
- Stock balance: AccountId, AssetId, Quantity, NetExpenditure
- Stock posting: AccountId, AssetId, Quantity, Cost, Timestamp, TxnId
At this stage, it is also worth establishing rules concerning the creation and maintenance of each entity, as we have done so for our example scenario below:
- Account entities are created upon the creation of a user account and are immutable from thereon
- Asset entities are created upon the registration of a tradeable asset and are immutable from thereon
- Stock balance entries are created when an account holder acquires shares in a particular asset for the first time. From thereon, each time an account holder is involved in a trade concerning said asset, the applicable stock balance entry is updated accordingly.
- Two stock posting entries are created each time a trade occurs (one for the credited party, and one for the debited party). These entries are intended to illustrate the net effect of the transaction on an account holder’s position in relation to a specific asset, and are immutable from thereon.
2. Identify data access patterns
When designing tables harnessing NoSQL databases such as DynamoDB, understanding access patterns is fundamental to the creation of schemas that minimise the need for complex queries and joins, without compromising on read performance.
Having established your use case and defined your data entities, you should have a good idea of how these entities are to be utilised and accessed, both internally and externally. Outlining each expected interaction is a crucial first step which establishes the necessary boxes to tick when defining queries later on.
For our example, the business has determined that the register will be accessed internally in the following ways:
- Before executing a trade, the backend logic should perform a lookup using the AssetId specified in the request to confirm that the asset in question exists
- Before executing a trade, the backend logic should perform a lookup using the AccountId specified in for either party in the request to confirm that the accounts exist
In addition to this, it is decided that the table should be made externally accessible for the following purposes:
- Account holders should be able to view a complete account summary consisting of their account data, all existing balances, and recent transaction history
- Account holders should be able to view a summary of their balances in relation to all assets that they own
- Account holders should be able to view details of their balances relating to a specific asset
- Account holders should be able to view their complete transaction history with regards to a specific asset. These results should be returned in descending order, based on the timestamp assigned to the entry.
3. Design the data model and define queries
Following the analysis carried out during step two, you should have an effective checklist of queries to accommodate, which should form the basis of the primary key design for each of your entities.
In our worked example, we arrived at six query combinations that we need to facilitate, so let’s work through them chronologically.
For every entity, we will name our partition key ‘PK’ and our sort key ‘SK’. Issuing the same field names to all entities assists in instances where we may wish to retrieve various entities via a single query. We will also prepend dynamic values within our ‘PK’ and ‘SK’ fields with strings that help describe the entities in question which will also prove useful when forming our queries.
Asset
The first query requirement concerns the asset entity, and simply requires that we are able to query assets by their AssetId value. This is the only instance in which the asset entity needs to be queried, so devising a primary key is fairly straightforward.
- PK: ASSET#<AssetId>
- SK: ASSET#<Name>
Using the primary key design above, you can query an asset using the following a key condition expression represented by the following pseudocode: ‘PK = ‘ASSET#<AssetId>’’
In this instance, the partition key alone is able to identify our asset, rendering the sort key somewhat redundant, so you could in theory populate this with whatever you wanted, although we have chosen to make our asset queryable by a combination of AssetId and Name if required.
Account
The next two requirements concern the account entity. The first of which necessitates a lookup using the AccountId value to verify that the account exists, while the second requires that we capture the account entry, in addition to all stock balance and stock posting entries associated with that account.
It’s worth acknowledging at this stage that all remaining query requirements are account-specific, so it makes sense to assign the same account-specific PK design to all account, stock balance, and stock posting entities, while using the SK field to differentiate them from one another.
- PK: ACCOUNT#<AccountId>
- SK: ACCOUNT#<AccountId>
Using the primary key design above – and a PK that will be shared with the stock balance and posting entities – we can satisfy both query requirements, as illustrated by the following pseudocode:
- ‘PK = ‘ACCOUNT#<AccountId>’’ alone will return the account in question, along with all applicable stock balance and posting items
- ‘PK = ‘ACCOUNT#<AccountId>’ AND SK = ‘ACCOUNT#<AccountId>’’ ensures that the account item alone will be returned
Stock balance
Requirements four and five concern the stock balance entity. One requires that we return all stock balance entries associated with a given AccountId value, and the other necessitates that we drill down into stock balance entries that match both an AccountId and AssetId value.
- PK: ACCOUNT#<AccountId>
- SK: STOCKBALANCE#<AssetId>
The above primary key design for stock balance items enables the required queries, as demonstrated below:
- ‘PK = ‘ACCOUNT#<AccountId>’ AND BEGINS_WITH(SK, ‘STOCKBALANCE’)’ will return all stock balance items associated with an account
- ‘PK = ‘ACCOUNT#<AccountId>’ AND BEGINS_WITH(SK, ‘STOCKBALANCE#<AssetId>’)’ identifies a particular balance entry for an specific account holder and asset
Note the introduction of the BEGINS_WITH operator, which can be used to evaluate the beginning of the sort key value and return items matching the operand provided. By populating it with the ‘STOCKBALANCE’ prefix alone, we ensure that all applicable stock balance entries are returned, while extending this to include the AssetId value enables us to specify a single item.
Stock posting
The final requirement asks that we enable account holders to access their complete transaction history concerning a specified asset, with the expectation that results are returned in descending order.
- PK: ACCOUNT#<AccountId>
- SK: STOCKPOSTING#<AssetId>#<Timestamp>#<TxnId>
This primary key design for stock posting items satisfies these needs and can return the desired results via a query along the following lines: ‘PK = ‘ACCOUNT#<AccountId>’ AND BEGINS_WITH(SK, ‘STOCKPOSTING#<AssetId>’)’
Note the inclusion of the Timestamp value within the sort key. The Timestamp value will be generated and written to the stock posting item at the point of its creation. Though this isn’t included in the query itself, this value will be used by DynamoDB to sort the items matching subsequent queries.
However, by default, DynamoDB returns items in ascending order. To reverse this to descending order as per our requirements, some additional configuration is required to set the ‘ScanIndexForward’ parameter to false, as shown in the code snippet below.
{
TableName: 'Register',
KeyConditionExpression: 'PK = :PK AND SK begins_with(SK, :SK)',
ExpressionAttributeValues: {
':PK': {
S: `ACCOUNT#${AccountId}`,
},
':SK': {
S: `STOCKPOSTING#${AssetId}`,
},
},
ScanIndexForward: false
}
Finally, the inclusion of the TxnId value at the end of the sort key is a safeguard to protect against the unlikely event that two stock posting entries with an otherwise matching primary key are generated, to negate the risk of these entries – which are supposed to be immutable – being overwritten. In our scenario, a TxnId value is randomly generated for each pair of stock posting entries upon their creation.
4. Build the table
Having designed your table to satisfy all of your data access requirements, the final step is to put it all together. For this process, we recommend using NoSQL Workbench, which is a client-side application designed to help developers model, visualise, and query DynamoDB tables more effectively.
Having created a new data model within NoSQL Workbench containing our ‘Register’ table, via the ‘Data modeler’ tab, we have assigned our primary key attributes to the table, alongside all other unique attributes that were identified for our data entities in step one. Note that, whereas certain fields, such as AccountId and AssetId, span multiple entities, they only necessitate a single attribute within the model.
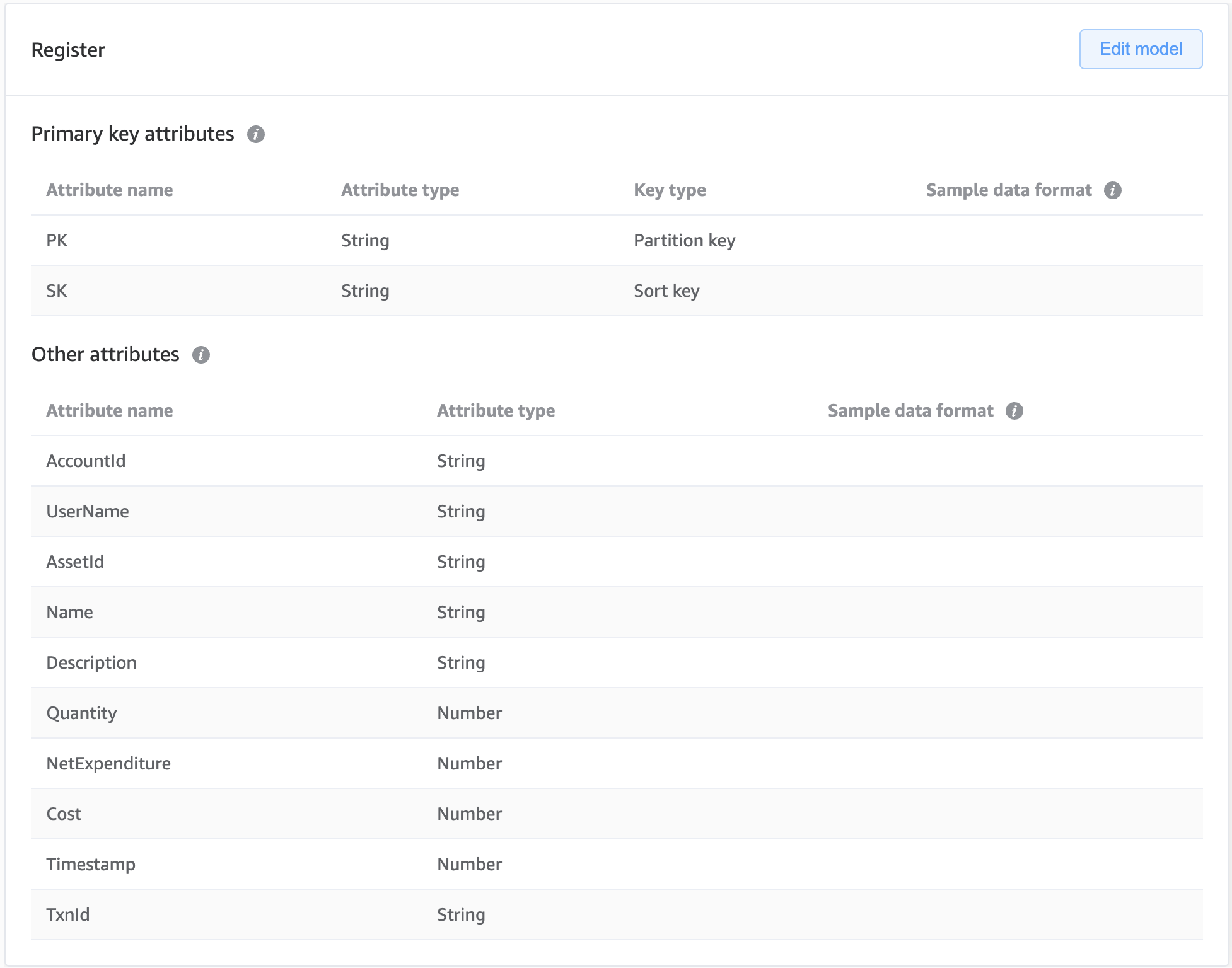
Next, via the ‘Visualizer’ tab, we populate our table with some sample data, consisting of a handful of entries that span our four entities and abide by the primary key formats specified in step three.
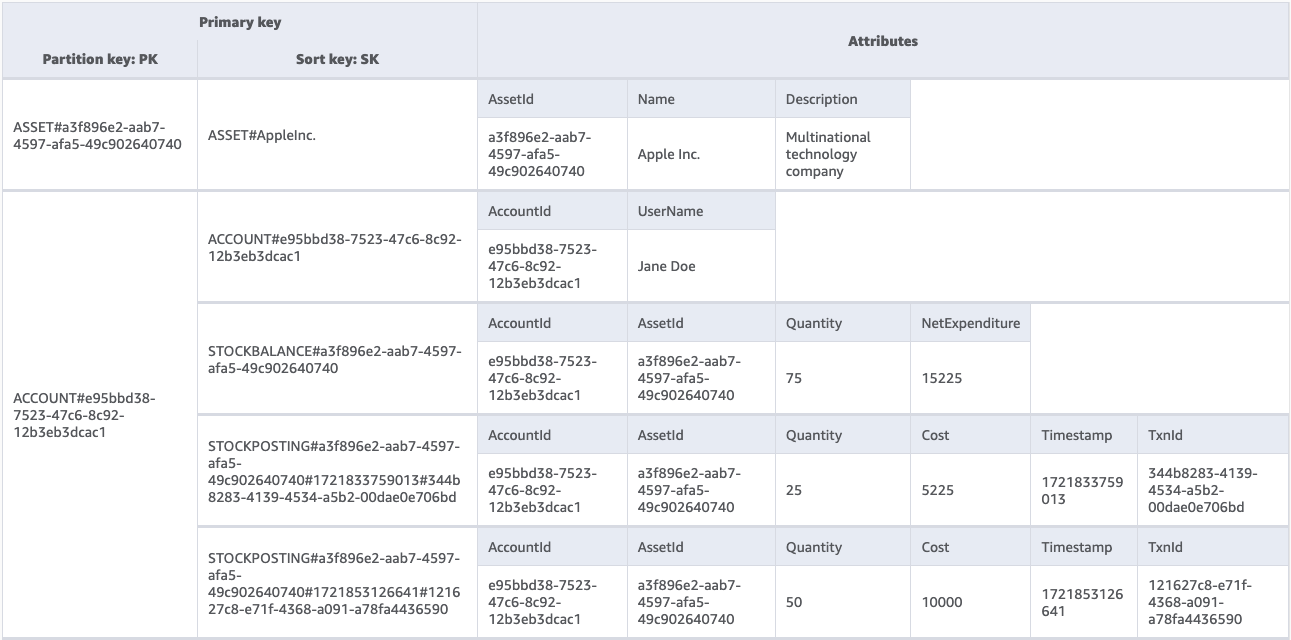
After adding the sample data, the ‘Aggregate view’ pane provides a helpful visualisation of each entry which identifies attributes shared by items while effectively compartmentalising individual items and entities within the single table design. All of which helps to paint a clearer picture of how individual items are queried and accessed. See our example below, which includes entries illustrating account holder Jane Doe’s ownership of shares in Apple Inc.
Adding functional flexibility through GSIs
Despite your best efforts, not all use cases can be satisfied solely by your default primary key, or requirements may surface later on that were initially not identified during the initial data modeling process. To overcome these challenges, and offer some much needed flexibility, DynamoDB enables the creation of Global Secondary Indexes (GSIs).
This is a powerful feature that enables developers to create additional access patterns by effectively establishing alternate primary keys. Having created a GSI consisting of a new partition key and sort key combination, referencing this GSI in a subsequent request will ensure that those keys are used to query the table, providing refined access to items that otherwise may not have been possible.
Returning to our example scenario, following the implementation of our single table design, the business has belatedly identified another query requirement whereby account holders should be able to view their complete transaction history spanning all assets owned, with all stock posting entries returned in the order that they were created.
Attempting to achieve this by querying the existing stock posting primary key (shown below) while only including the ‘STOCKPOSTING’ when querying the sort key wouldn’t work. This is because DynamoDB returns items alphanumerically by default, and so items with matching AssetId values would be arranged together before the Timestamp values are evaluated.
- PK: ACCOUNT#<AccountId>
- SK: STOCKPOSTING#<AssetId>#<Timestamp>#<TxnId>
This scenario requires the removal of the AssetId value from the sort key, but it serves an existing purpose, so an alternate solution would be to create a reserve sort key with that attribute omitted, as shown below:
- SK2: STOCKPOSTING#<Timestamp>#<TxnId>
After creating a GSI named ‘GSI1’ consisting of our original partition key and our ‘SK2’ field as the sort key, some minor tweaks to the parameters that we shared during step 3 (note the ‘IndexName’ specification and the refinement of the ‘:SK’ value below) will enable us to satisfy the newly defined access requirement.
{
TableName: 'Register',
IndexName: 'GSI1',
KeyConditionExpression: 'PK = :PK AND SK begins_with(SK, :SK)',
ExpressionAttributeValues: {
':PK': {
S: `ACCOUNT#${AccountId}`,
},
':SK': {
S: 'STOCKPOSTING',
},
},
ScanIndexForward: false
}
Conclusion
DynamoDB’s single table design demonstrates that it is possible to design a highly performant and scalable database that doesn’t suffer from the computational overheads that typically trouble relational databases, while also enabling complex queries and wide-ranging access patterns. It just requires a bit of foresight and an orderly approach.
If you have any questions or need assistance implementing a custom DynamoDB solution, don’t hesitate to contact us. As a specialised partner, we are here to help you maximise the potential of your database systems and ensure the success of your technology projects – contact us today!


Contact our team and discover the cutting-edge technologies that will empower your business.
Talk to our experts!
contact us


